
The purpose of this post is to summarize my thoughts and points I came across the SQLBits (web|twitter) conference. The points are not explained into detail as they serve as reminder of topics that are important and have to be looked into. I use them to possible key words for deeper research on the topic covered during the presentation. This is just a tip of iceberg I gained during the four days, so if you are interested in any of these topics in more detail feel free to reach out to me. I’ve included a link to each session, which should be available as recording for free, each speaker’s blog and twitter account where you can find as well a lot more on each topic. Enjoy!

Day 1
From 0 to DAX
Speaker: Alberto Ferrari (blog|twitter)

Notes
-
Mind shift between Multidimensional and Tabular
- Use more calculated measures (CPU) rather than calculated columns (RAM)
- CPU is much, much faster than RAM
- Smaller models are faster
-
Filter context
-
Automatically on table filtered by selections
- Row
- Column
- Filter
- Slicer
- Not changed by FILTER function
- FILTER changes the table, but not the filter context
-
-
Row context
- Automatically for each row
- Iterates through rows in table
- Does not filter anything
-
FILTER function
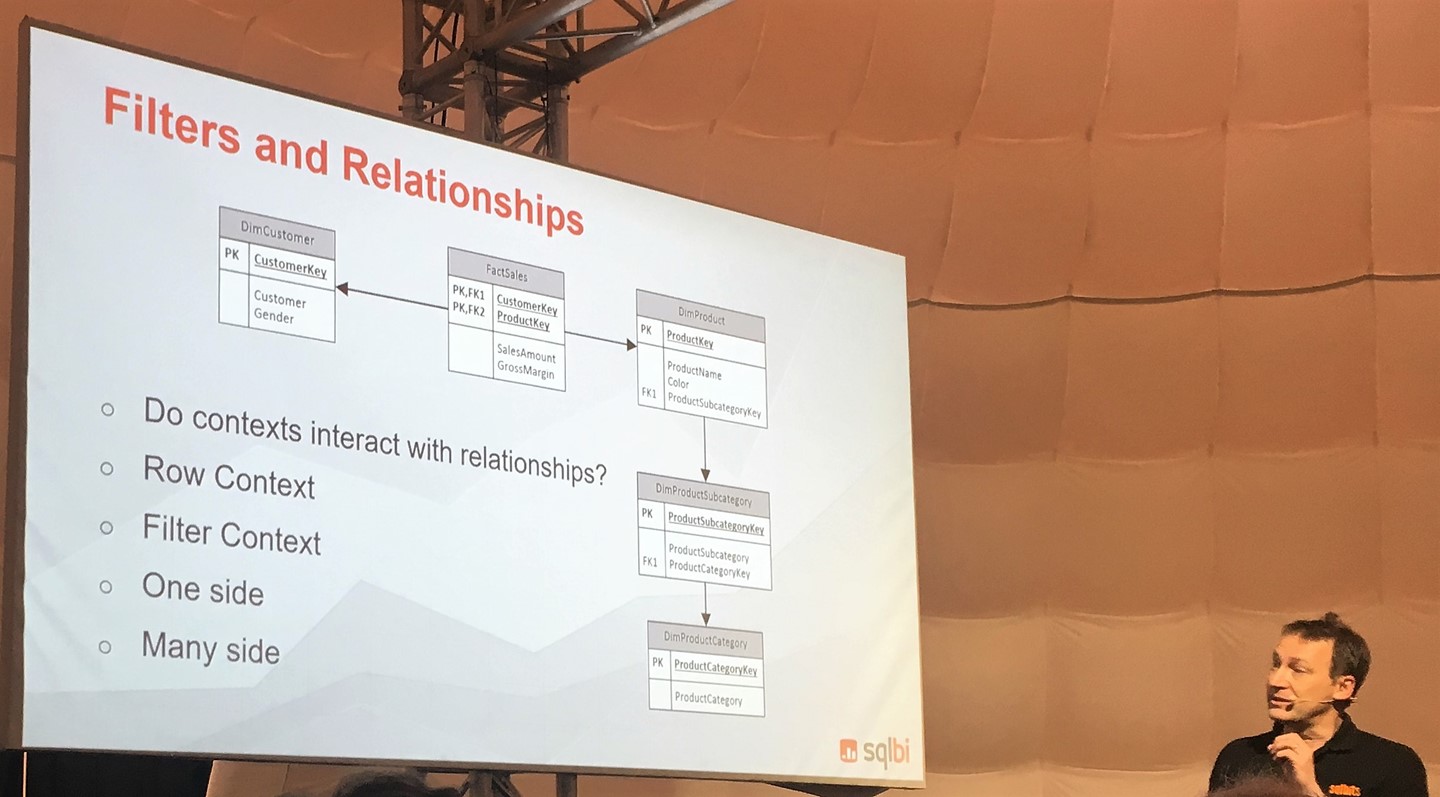
- Contexts and Relationships
- Go by default from many to one not from one to many
- Cross-filter direction filters as well from fact table to another dimension
- Alberto: “Result is correct but nobody understands it. It’s a strange definition of correct.”
-
Context Transition
- Performed by CALCULATE
- Row context transforms into filter context
- Calling measure is automatically surrounded by CALCULATE
- Never add a table name in front of a measure – Alberto: “If you do it, you go to hell!”
-
Troubleshooting issues
- Stop thinking
- Look at filter context and how it is applied
- Use only one Date table in model
Day 2
Columnstore Indexes-the practical solutions
Speaker: Niko Neugebauer (blog|twitter)

Notes
-
Columnstore Archive Compression
- Better
- For data not used frequently
- Can separate on partitions
-
Dictionaries
- Do not use strings on fact tables
-
Dictionary pressure
- If dictionary is over 7MB it cuts down your row groups and slows down the performance
- If you have too large dictionaries (more than 100k rows) they are not used to use predicate pushdown for strings
-
Global dictionary
- Each partition has its own dictionary
- Niko: “Strings are evil!” 🙂
-
Use bulk load to load data directly to CI
- Use magic number to avoid Deltastore
-
Do not use CI with In-memory optimized tables
- not production ready, more problems than solutions
-
Hammer DB
- Generate test databases with lots of data
- http://www.hammerdb.com/
- Batch mode is the gamechanger not compression
-
Partitioning
- Make sure how big the row-groups are in your partitions
- Each partition = min. 1 rowgroup
- Be wise with partitioning
- It’s not a performance feature, but a data management feature
-
In case of large strings and data dictionary pressure
- Create a NCI and avoid the large column
- Look at trim_reason_desc = NO_TRIM => this is ideal
Day 3
Columnstore killed the OLAP Star-Did it really?
Speaker: Gabi Munster (blog|twitter) and Niko Neugebauer (blog|twitter)

Notes
- Hard to find people skilled in both
- Hardware is not as easy to get as everybody says
- If going to Azure check your requirements
- Beware of dictionary pressure with Columnstore and page trimming
- CI can perform on complex queries, but requires lot of knowledge writing it
-
Three factors for evaluation
- Performance
- Hardware cost
- Expert person cost and availability
- In some cases, Tabular can run circles around columnstore. #performance
- Semantic model is the main aspect for SSAS
-
Modern Datawarehouse requires combination of various data sources
- Tabular is comfortable here
T-SQL : Bad Habits and Best Practices
Speaker: Aaron Bertrand (blog|twitter)
Notes
- Check out SQL Plan Explorer
- Presentation for this on SentryOne blog
- Great to review your T-SQL habits
- Act 1 Stay consistent
- Act 2 Use dates properly
- Act 3 Get predictable behavior
- Act 4 Query efficiently
Introduction to Azure Analysis Services
Speaker: Chris Webb (blog|twitter)

Notes
- SSAS Tabular on cloud
-
Be aware which subscription you use
- Might happen that you deploy with wrong cached account
- Using standard development tools
- REST API for automation
-
Main drawback is the cost
- It’s in preview
- Opens new usage scenarios of maturing Power BI
Optimizing multi-billion row tables in Tabular
Speaker: Alberto Ferrari (blog|twitter)


Notes
- Do not store primary keys of fact tables
- Care much more about cardinality rather than data type
- Segments not smaller than partition
- Parallelism is driven by segments not partitions
-
Create benchmark for optimizing columns
- Time of Sum
- Time of DistinctCount
-
Hardware is super-important
- Have the fastest cores you can have
- Be aware of NUMA mode of your server
-
Be aware of relationships
- 1M on dimension
In-database Predictive Analytics with SQL Server vNext
Speaker: Sacha Tomey (blog|twitter)

Notes
- Be a careful to select direct query vs. import
- If you do not have gateway you can have some options with OneDrive
- Carefully name the data sources in gateway according to actual server and database names
Power BI Gateway
Speaker: Adam Saxton (blog|twitter)

Notes
- Map users between AAD a AD
Day 4
Database Design Throwdown
Speaker: Karen López (blog|twitter) and Thomas LaRock (blog|twitter)

Notes
- Karen “Your main job is to keep your boss out of jail!”
- Karen “Just in case is a lousy design pattern.”
- Make the design decision on Cost, Benefit, Risk
- Use sequences instead of identity
- Start from lowest number not 1
-
Script for identity analysis from Tom’s blog
Building Blocks of Cortana Intelligence Suite in Azure
Speaker: Melissa Coates (blog|twitter)

Notes
- Overview of Azure services forming Cortana Intelligence Suite
- Presentation on Melissa’s site
-
Azure Data Analytics
- Currently not usable for ad-hoc queries
-
Azure Machine Learning
- Look at it as Import/Export Wizard in SSIS
- Helps you to start quickly and learn advanced analytics before you advance to own customized algorithms
Using M for data access in Analysis Services Tabular v.next
Speaker: Chris Webb (blog|twitter)

Notes
- Azure adventure works from Redgate
-
Query folding for load performance
- SQL server
- SSAS
- Odata
-
Lot of new small SSAS model
- Will grow up and will need to scale
-
Direct query
- SSAS as new semantic layer on Big Data / Cloud sources
- Partitioning with M in SSAS