
Introduction
Recently have been working on a “Proof of Concept” task where I wanted to test the capabilities of Azure Analysis Services Tabular model when loading data from different sources (hot path and cold path) into a single table with multiple partitions.
The main reason why this POC was required was the fact that one of the architectures we were discussing with the team was designed with two paths:
- hot path – incrementally processed hot data would flow quickly through this path,
- cold path – archived or batch processed cold data would flow through this path.
The basic set up is shown in the diagram below:
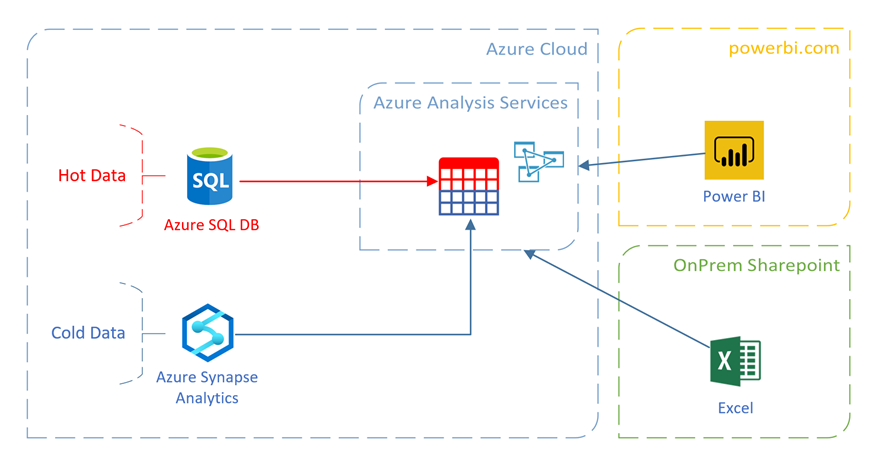
Note: obviously, the source for the Tabular table partitions does not have to be only Azure DB or Azure Synapse Analytics (as shown on the diagram above), but it can also be Azure Data Lake Storage – as described in this amazing blog post written by Jorg Klein.
Proof of concept implementation
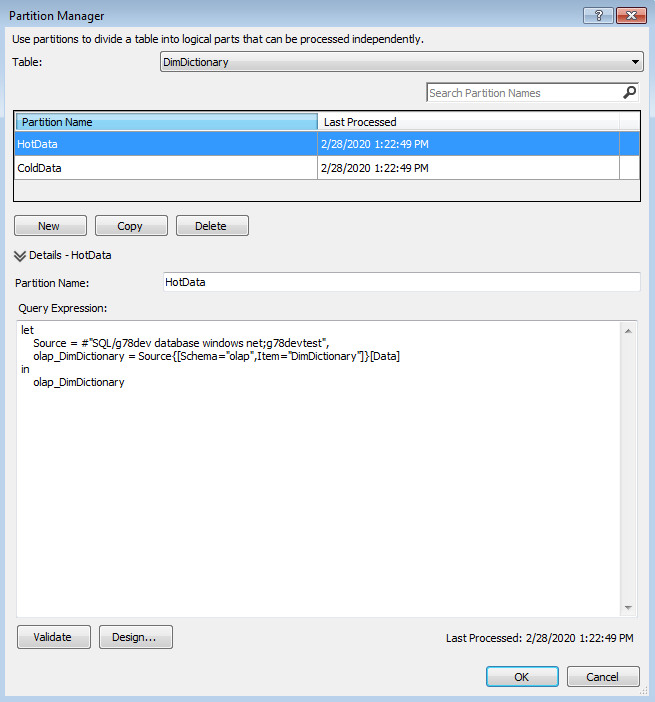
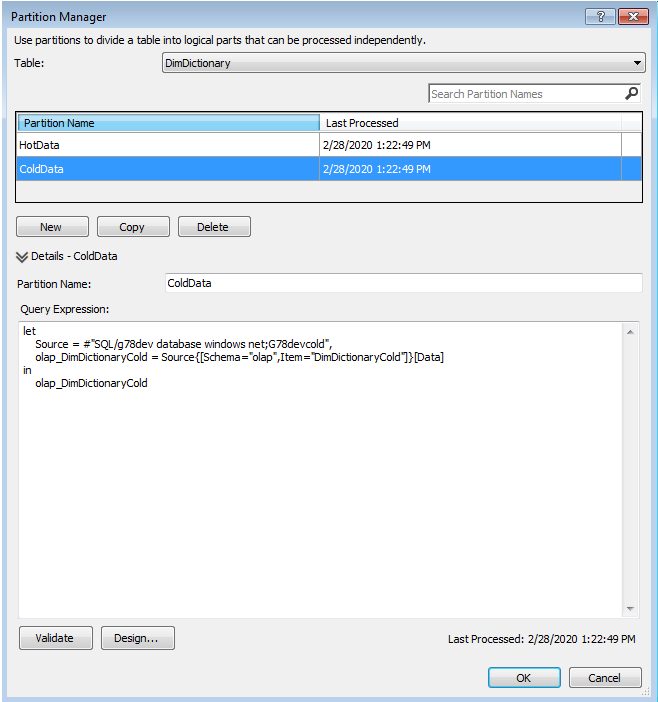
To simplify the POC task, I created a new Tabular Model with a single dummy table called DimDictionary that had just two columns: Code and Description. Then, I decided to create two partitions for this table: ColdData and HotData.
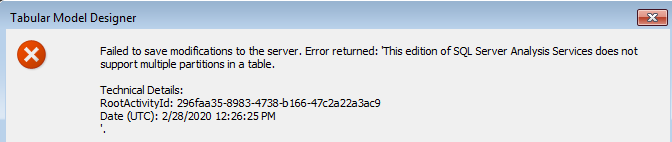
Unfortunately, I got the following error message when tried to create the second partition and deploy my tabular model to Azure:
“This edition of SQL Server Analysis Services does not support multiple partitions in a table.”
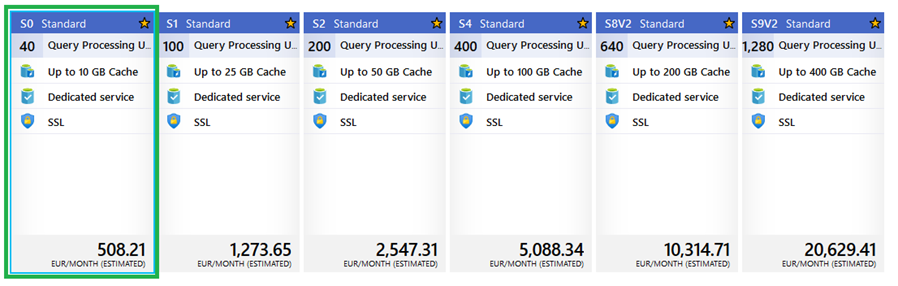
Quite quickly, I realized that the Basic tier does not support multiple partitions in a table, and it is required to upgrade my Azure SSAS to a higher (at least S0) pricing tier:
Once upgraded, I was able to create the second partition and use different data sources (completely different databases) for each partition as shown below:
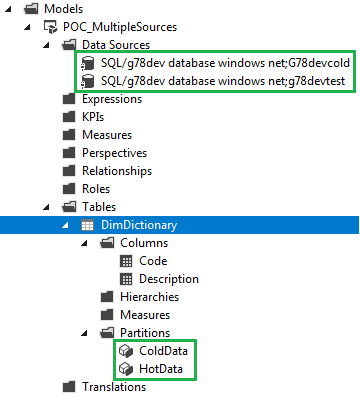
Here are the definitions of both table partitions (as you can see, the source is different for each partition):
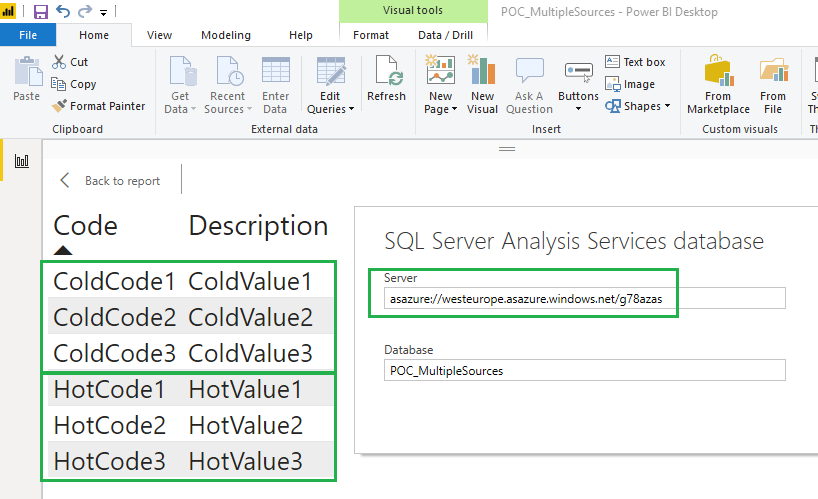
After I deployed the Tabular model to Azure and processed, I was able to access both, Hot and Cold data in one DimDictionary table using Power BI:
Conclusion
Processing data from multiple sources into one single table with multiple partitions can be quite handy in some scenarios, especially, when having the Lambda Architecture or the Hub & Spoke architecture in place.
You must bear in mind that the Basic tier is not enough for this purpose and you will have to use the Standard tier (corresponds to Analysis Services in the SQL Server Enterprise edition) for your Azure Analysis Services project.
Sources
Azure Analysis Services pricing
Choosing tier in Azure Analysis Services
Jorg Klein – Multi-Source partitioned Azure Analysis Services tables
1 Comment. Leave new
Nice article! Partitions are also good for handling changes in data over time, where maybe the original table fields have changed.